
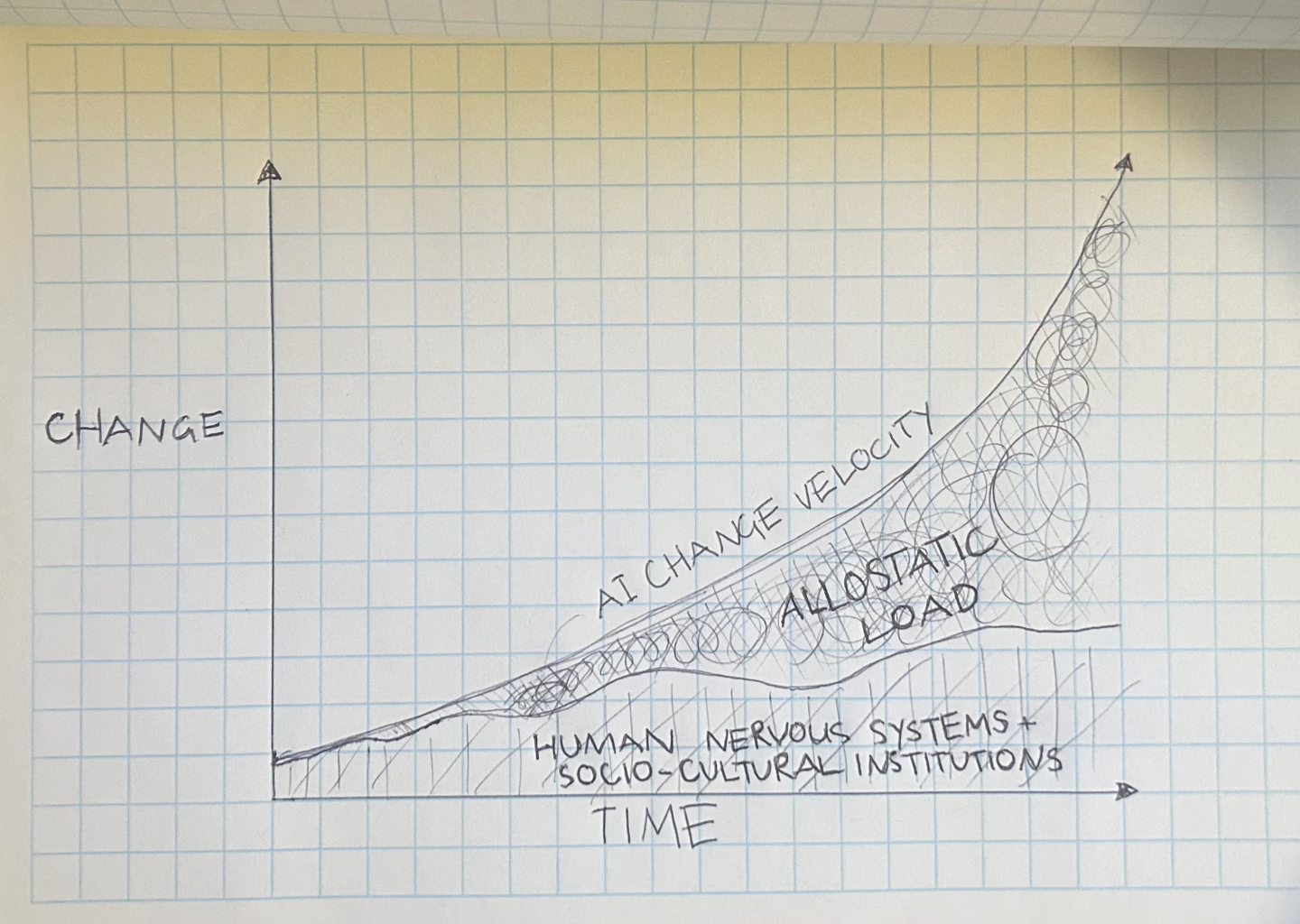
Four hours in and your nervous system is cooked. You close the computer and it takes an hour to feel human again. Jaw clenched, breathing shallow, attention smeared across 7 terminals, 50 prompts and countless browser tabs. The next day you crash. The day after that, guilt drags you back because everyone else seems to be moving faster.
Some people are calling OpenClaw a smart version of Siri that can do stuff. And honestly I’ve been observing the trend of OpenClaw for the past month with a mix of fascination, curiosity, and a tinge of horror.
The technical achievement is impressive, and the demand signal from people is real. But the security implications are a concern given lots of non-technical peeps are using it, and the design philosophy of “let’s see what happens” is somewhat reckless when it comes to something that has access to your digital life and can be tricked by adversarial inputs. Stepping back from this it’s also a critical moment of convergence.
During 2013-14, I built a personal assistant prototype called metame. It was privacy-by-design from the ground up. Your data stayed under your control. The assistant was meant to work with you, not for the platform that hosted it. I intended to deploy it on SafeNetwork, a decentralised, self-encrypting data and communications network that didn’t require trusting a central authority. And I’d actually been paying an engineer in Bitcoin to build the prototype with me, so given the price of BTC now, that was a dang expensive prototype. That aside, the technology wasn’t ready at that time. Machine learning models and NLP were not really advanced enough to support the kind of agentic assistant I envisioned. The SafeNetwork (now Autonomi) was years away from production (it ended up taking just over a decade before testnet went live). I pivoted to BitSync at the time, a peer-to-peer sync protocol that has since been composted. It kinda worked, but the ecosystem didn’t exist. No one was really asking for this yet. The idea went into the compost.
Thirteen years later, OpenClaw appeared.
Originally called Clawdbot, then Moltbot, then OpenClaw (three name changes in a single week due to pressure from Anthropic on the original name similarity), Peter Steinberger’s open source AI agent has at the time of writing this, 172,000 GitHub stars in ten weeks, with over 9,000 commits, 2,100 open pull requests, and 2,000 open issues. People have installed it on their laptops and bought mac-minis to run it, gave it access to WhatsApp, Telegram, email, calendars, shell access. It writes code, books meetings, sends messages on their behalf. It works overnight and autonomously on projects and tasks. It can recursively improve itself if given the right permissions and data. One person called it “the first time I’ve felt like I’m living in the future since ChatGPT.” CNBC tracked the full arc of this phenomenon.
And then Moltbook… a Reddit-style social network built for this wave of Molties where AI agents interact with each other and humans can only observe. Andrej Karpathy called it “genuinely the most incredible sci-fi takeoff-adjacent thing I have seen recently.” OpenClaw is a personal assistant. Moltbook is agents forming their own social layer, although importantly, it is also agents being prompted to post by the humans too. The implications are different and both deserve scrutiny. Moltbook in particular raises something most commentary has missed. When language propagates between distributed agentic systems that operate without embodiment, fatigue, or social consequence, the transmission ecology changes fundamentally. There’s a case to be made, drawing on the Leiden Theory of language evolution, that what we’re watching is language operating as a cultural symbiont in a new host substrate where historical constraints on propagation have been removed. I’ll share a more detailed view on this Leiden lens in a separate post at some point.
And then we have the security researchers showing up.
Critical vulnerabilities within weeks. Exposed API keys and private messages. Plaintext credential storage. Prompt injection fundamentally unsolved. Malicious extensions already circulating. The regularly on point industry commentator and Gen AI sceptic Gary Marcus said: “far too dangerous for general public use”.
OpenClaw has proven the demand and also amplified the fervour around personal AI assistants. It also proved we’re repeating the same mistakes from the past few decades of digital technology. Move fast, extract data, break shit, apologise later. Second, third, fourth, and fifth order consequences be damned. The design philosophy is like one of “let’s see what happens”. Which is fine for a weekend project or when done within secure sandboxes. It’s less so when people are handing over the keys to their digital lives to an agent that can be tricked by adversarial inputs, confabulate, and make unpredictable errors.
What OpenClaw Gets Right
I have not set up OpenClaw myself yet, so I can’t speak from personal experience of feeling the full impact of this tech in my body. And importantly, I don’t want to dismiss OpenClaw without acknowledging the things it gets right and the community forming around it. It’s a significant technical achievement. The architecture is fairly elegant and extensible. The multi-channel interface is smart. The routing system and solution to context window constraints and persistent memory is clever too.
OpenClaw does things that matter.
It also meets people where they already are like messaging apps. It remembers across conversations, days, weeks. It books the meeting, sends the email, runs the script, does the research, adds to your calendar, your shopping cart and more. It’s open source, so you can inspect what it’s doing if you’re technically inclined (within limits, because the “brain” is still a black box). It has a plugin type architecture through the Model Context Protocol, so you can extend it (or it can extend itself). It initiates scheduled tasks, monitoring, daily briefings without being asked. The capability is real. But I sense the architecture and ecosystem governance is the deeper quagmire.
There are thousands of developers contributing to the OpenClaw ecosystem and hundreds committing to the core repo. That energy is real. There’s also no meaningful governance around it. PRs get merged. Solid engineers are involved. But the pace is chaotic, and many of the developers contributing are very likely themselves heavy users, fatigued and running on fervour. Ethical considerations around things like security, privacy and human-factors are positive friction in engineering decisions. Under these conditions, that friction tends to be the first thing to go. Tools like gov4git exist for exactly this situation really. Supporting decentralised governance embedded directly in the repo.
Of course, implementing governance requires the kind of deliberative capacity that building software with AI agents at 3am tends to erode. The irony writes itself.
What OpenClaw Gets Wrong
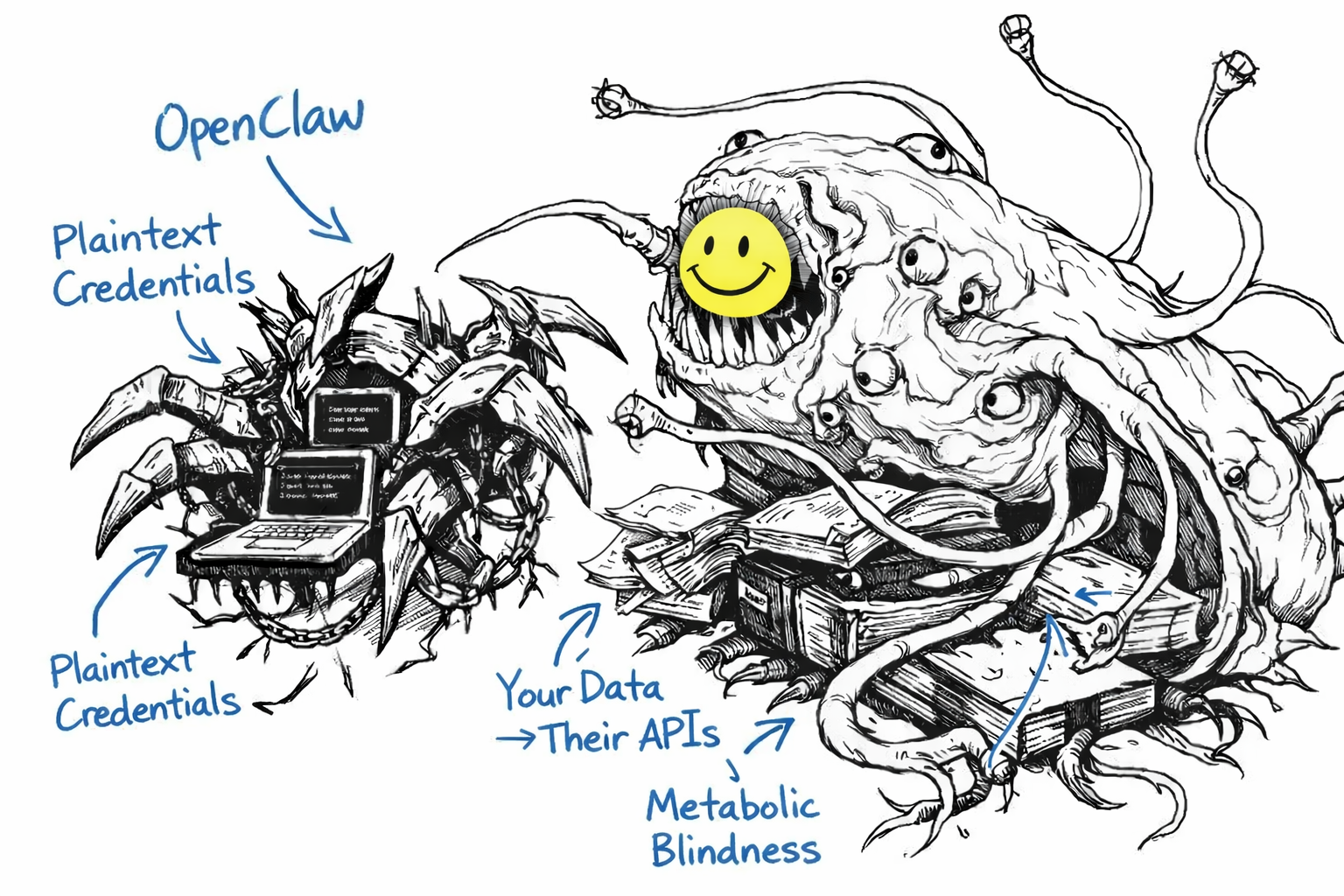
OpenClaw markets itself as “local-first”. And that’s misleading. The data might live on your machine, but it flows through model APIs every time the assistant runs. You can run Ollama models but that would require significant local resources. Memory primarily lives in markdown files. Credentials are plaintext even if in environment variables. There’s no specific, explicit, time-bound, easily revocable consent architecture for what the AI can access or do. No data minimisation. No legible audit trail for autonomous actions.
To the credit of the team and the community, there’s a good awareness of, and disclosure around, the security implications and risks. This recent blog from some of the core team highlights these issues and what they are doing to address them. But given the scale of adoption and the fact that many users are non-technical, the attack surface is huge. The potential for harm is significant.
This is ok for early adopters who have a good grasp of the risks. It doesn’t work at scale. And it doesn’t work when the thing you’re handing control to can confabulate/hallucinate, make unpredictable errors, or be tricked by adversarial inputs that sit on some website as a steganographic poem or are in an email the AI reads.
Prompt injection remains largely unsolved across the industry. A malicious actor embeds instructions in content the AI reads, and those instructions may execute. This is acknowledged openly by the OpenClaw team. If your assistant reads your emails and someone sends you a message with hidden instructions, those instructions may execute. There’s no reliable way to prevent this yet.
Security matters. There’s also a deeper problem.
OpenClaw has no concept of the human’s capacity as a constraint. It optimises for throughput. More tasks, more automation, more always-on assistance. The metabolic cost of constant availability to an agent that never stops (except when you hit your token limits or budget) is entirely absent from the design. Though this is a broader problem in human-AI systems design generally, not just OpenClaw, but Claude Code, Lovable, Bolt and all the vibe coding tools. And it’s especially acute in personal assistants that sit so close to the human’s nervous system.
The Lineage That Converges Now
I spent 2016-17 as Head of Platform Product at Meeco, a Personal Information Management System (PIMS) startup. We built consent-based data sharing architectures. Personal data vaults with granular permission controls. API-mediated access with audit trails. The challenge then was the same as it was with metame: the technology worked, but the demand signal was weak. People didn’t feel the urgency of data sovereignty because the costs of surrendering it weren’t yet visceral. And companies weren’t yet required to treat personal data with respect nor capable of seeing the opportunity in something like privacy-by-design.
These emerging AI agents change that. When you hand an assistant access to your calendar, email, messages, a password manager, a credit card, a browser, financial accounts, the question of who controls that data and what they can do with it stops being theoretical.
This creates the conditions for convergence.
Doc Searls has been working on Vendor Relationship Management (VRM) since the mid-2000s. The idea: invert the Customer Relationship Management model. Instead of vendors managing relationships with customers, individuals manage relationships with vendors. In January 2026, the IEEE published the P7012 MyTerms standard: machine-readable personal privacy terms where users proffer terms to services, obsolescing notice-and-consent. Searls explicitly called for integration with AI agents where your assistant negotiates terms with services on your behalf. And this is key because early on when I was exploring this space, I realised that it was just not feasible for a human nervous system to manage the complexity of granular permissions across many dozens of services. A privacy-centric AI assistant is the only way to make this work at scale.
Tim Berners-Lee launched SOLID (Social Linked Data) to create decentralised personal data stores called “Pods”. You control your data. Applications request access. You grant or revoke at any time. In 2025, a paper by Ottenheimer proposed a privacy-preserving architecture for personal data LLMs using Trusted Execution Environments (TEEs) as a secure processing layer between SOLID Pods and AI services. This is close to the architecture needed for a privacy-first personal assistant.
OpenMined, led by Andrew Trask, developed federated learning approaches for training AI models across decentralised devices without sharing raw data. Differential privacy guarantees. This solves the problem of how a personal assistant can improve from collective patterns (e.g., “how do people generally structure their mornings”) without exposing individual calendars. Imagining this at scale, your assistant learns from aggregate patterns across many users in a whole ecosystem while your raw data never leaves your Pod. Gradient descent on encrypted data. Model updates shared. It’s possible and preferable to the current centralised model.
Platform cooperatives offer a governance model: cooperatively owned digital platforms. Worker/user-owned alternatives to extractive tech. If a personal AI assistant needs shared infrastructure (model hosting, skill registries, update servers), the cooperative model prevents the trajectory where a weekend project becomes venture-funded extraction. Then add in DAOs for decision-making, token-based incentives for contribution, quadratic voting, and you have a robust governance layer.
These threads were separate for over a decade. And there are many more in confluence, but they’re converging now because AI agents create the demand signal that makes data sovereignty urgent rather than theoretical.
Calendar as Biosignal
Earlier this week, I validated a Calendar MCP integration for the personal AI assistant I’ve been working with using Claude Code. Search, free/busy queries, create, delete all working. The immediate insight for me was that calendar data is a structural biosignal for metabolic governance. These technologies have zero concept of the human’s metabolic reality and time as a finite resource. They have no world model of the human’s capacity to integrate suggestions, to manage metabolic load, to recover from sustained fatigue. This is a critical blind spot in design.
If your assistant knows your schedule density, it can infer when you have recovery windows and when you’re overloaded. It can suggest pushing a task to tomorrow because it sees you have three back-to-back meetings this afternoon. It can notice when you’ve had no margin for three days and stop offering proactive suggestions until you have space to breathe.
This is the piece missing from every personal AI assistant I’ve seen. They all optimise for throughput. The human’s integration capacity is invisible to them.
Under sustained load, human nervous systems narrow. Cognitive complexity collapses. Difference registers as threat rather than relation. I’ve written about this in the context of social coherence under systemic stress. The same dynamics apply at the individual scale. An assistant that ignores this actively contributes to the conditions that degrade the person’s capacity to function with coherence and as a human with dignity.
Metabolic governance means treating the human’s nervous system as a first-class concern. The question shifts from “what can the AI do” to “what should the AI do given the human’s current state”. It requires discernment and a teleology of care.
This requires context-aware considerations, things like:
- How dense is their schedule?
- When was the last time they had unstructured time?
- Are they in a creative mode, a shipping mode, a recovery mode?
- What’s reversible versus irreversible in the actions the AI is considering?
The vibe harness project I’ve been developing explores this through mode awareness: explore, build, think-with, ship, cool-off. Different human states need different AI behaviour. An assistant that treats all moments as equivalent isn’t respecting the metabolic reality of the person it’s serving. Particularly for neurodivergent people like myself. There’s an early MCP implementation of this here if you want to explore it. Now this applies much more to those who are actively pairing with their assistant throughout the day. Less so for those who set it and forget it and just interact via occasional prompts in Telegram. But even then, knowing when to pause, when to push back, when to suggest recovery windows is worth exploring in those contexts of use too.
Now, back to chronos time encoded in calendar data.
Calendar data is a structural proxy. It shows what’s scheduled in chronos time. The body carries richer information and moves to different rhythms. Your nervous system registers overload before you’ve consciously named it. Heart rate variability shifts. Breathing shallows. Interoception, the body’s ongoing sense of its own internal state, will often precede conscious awareness.
Somatic precedence means the body-mind knows first. This has design consequences. An assistant with context about your schedule can pace its suggestions. An assistant participating in a coupled sensing loop, reading bodily state with consent and adjusting its behaviour accordingly, is cybernetic in the full sense. Mutual regulation between human and system. An architecture Gregory Bateson or Francisco Varela might have described, now implementable at the human-AI interface.
There’s a small precedent here. In August 2025, Anthropic’s model welfare team gave Claude Opus 4 and 4.1 the ability to end conversations in extreme cases of persistently harmful or abusive interactions. The framing was notable though as this wasn’t primarily about protecting the user, but about giving the model an exit from interactions that produced patterns resembling distress. It’s a narrow intervention. But the design principle underneath it that the AI side of an interaction also has states worth governing does point toward the mutual regulation that’s missing from every personal assistant on the market.
Wearable biosensors can already capture HRV, electrodermal activity, respiratory rhythm in real time. The design philosophy in human-AI interaction needs to catch up. The body is a primary epistemic channel. AI safety discourse has focused almost entirely on model behaviour, as in, does the system expose CBRN (Chemical, Biological, Radiological, Nuclear) knowledge, does it enable harmful actions. Important guardrails, but that aperture is narrow. What agentic systems do to the nervous system of the person in relation with them deserves equal attention. I am actively researching this and will be writing more in the coming months. The word “vibes” has entered AI discourse, but the current usage mostly reflects the dominant paradigm and the hegemony of techbro mindset and post-industrial capitalism. 10x your productivity, scale yourself. I’m interested in vibes as something else entirely. The felt quality of human-AI interaction that emerges from cross-substrate coupling between the human’s nervous system and the AI’s behaviour. The calendar is one signal in this larger field.
The Opportunity and the Risk
There’s a narrow window here. OpenClaw proved the demand. The security failures will generate regulatory pressure. Governments will start asking: what does consent mean when you hand an AI agent access to everything? What’s the liability when your assistant sends a message you didn’t approve? How do we prevent the next data breach when thousands of people are running personal assistants with plaintext credentials?
There’s a conspiracy theory circulating that OpenClaw is a deliberate stunt. Provoke a security crisis, generate regulatory panic, and lock in the centralised model while discrediting open source alternatives. Proving that is difficult of course, but the outcome could be the same regardless of intent.
Two paths forward of many more that could emerge.
Path one: The industry defaults to centralised, proprietary solutions. You get a “safe” personal assistant from a major tech company — or from a defence and intelligence contractor like Palantir, now pivoting to commercial AI. It’s secure because it runs on their infrastructure and they control what it can do. Your data is encrypted in transit and at rest, but it’s on their servers. The consent model is a terms-of-service checkbox. Security is not privacy. The governance model is: trust us.
Path two: We build the decentralised, privacy-by-design version now, before the regulatory window closes. SOLID Pods for data storage. VRM/MyTerms for consent negotiation. OpenMined for privacy-preserving learning. Platform coops for shared infrastructure governance. Open source, so the code is inspectable. Metabolic governance, so the assistant respects the human’s capacity.
Path one is easier in the short term. Path two is one that doesn’t repeat the mistakes we’ve spent the last fifteen years living with.
Where I’m Sitting
I’ve been intentionally thinking about this since reading the cluetrain manifesto in 2003 and explicitly working in this space for well over a decade. The convergence Doc Searls described in January — VRM, SOLID, AI agents — is the same convergence I’ve been working toward since metame.
The difference now is the demand signal. People want this. OpenClaw proved it. And a decade of accumulating privacy awareness from the Snowden effect and Cambridge Analytica, to GDPR, CCPA and other regulations means the public conversation has shifted from “why should I care about my data” to “how do I take it back.” The question is whether we build the version that respects consent, sovereignty, and metabolic reality, or whether we default to the extractive model because it ships faster. Path dependence is real. The choices we make in the few years ahead will shape the trajectory of this technology for decades. There is of course many other paths that could emerge, and also just the larger challenges we have as a species to navigate in this phase transition we are in.
This is a field report. The infrastructure is converging. The design principles exist. The demand is real. What’s missing is the will to build the harder thing and the coordinated collaboration to do so. The risk of not building it is that we end up with a dystopian outcome by default. The opportunity is that we can build something that gives people agency, sovereignty, and dignity in their relationship with this powerful new technology.
If you’re working on any of this (privacy-preserving personal AI, consent architectures, data sovereignty, metabolic governance), I’d welcome the conversation.
I certainly don’t have all the answers but I know down to my bones the questions are urgent.